准备五台虚拟机分别如下:
ip 主机名
第一台 192.168.199.100 NameNode
第二台 192.168.199.101 StandbyNameNode
第三台 192.168.199.111 DataNode1
第四台 192.168.199.112 DataNode2
第五台 192.168.199.113 DataNode3
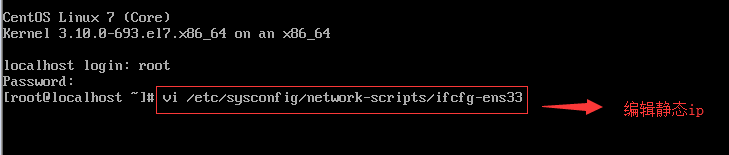
2.修改静态ip
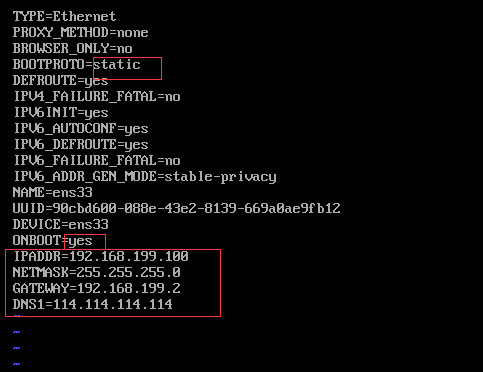
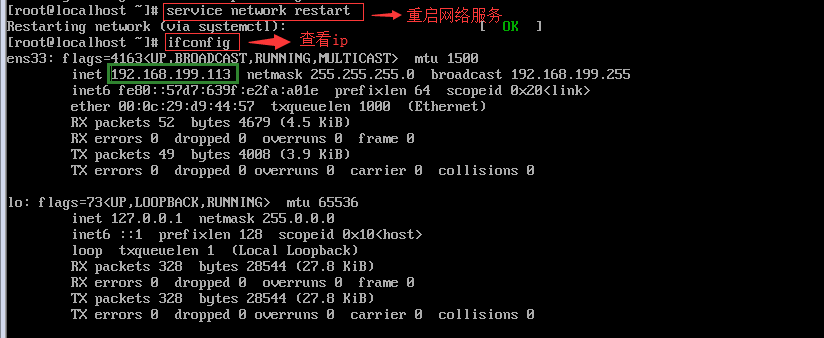
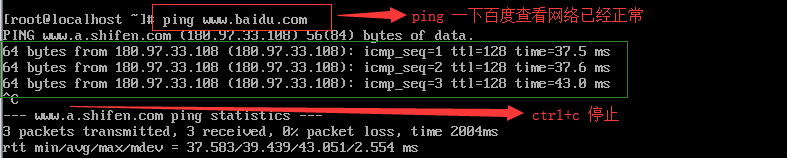
3.hosts解析编辑 vi /etc/hosts

4.主机名对应(每台电脑主机名修改为对应的值)
vi /etc/hostname
修改为对应的值后重启输入hostname查看是否生效

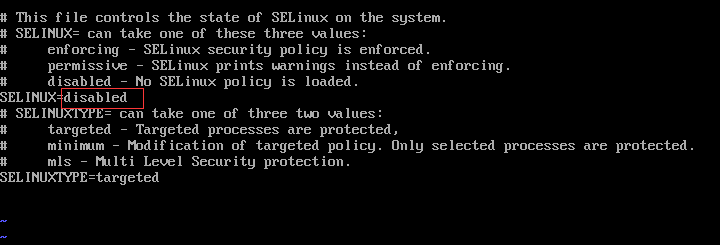
5.关闭防火墙和安全策略

vi /etc/selinux/config
6.下载Hadoop3.1和Java1.8到根目录下

7.分别解压
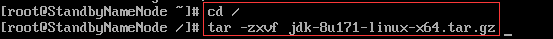
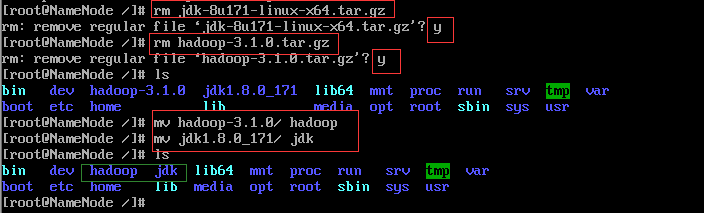
8.解压后删除压缩包并重命名(分别重命名为hadoop和jdk方便后期配置)
9.配置java和hadoop的环境变量
vi /etc/profile
在文本最后添加如图代码

source /etc/profile
使环境变量生效
10.配置ssh免密登陆
http://www.cnblogs.com/dxdxh/p/8989907.html
在~/.ssh目录下输入 ssh-keygen -t rsa然后一直回车后目录下会生成两个文件
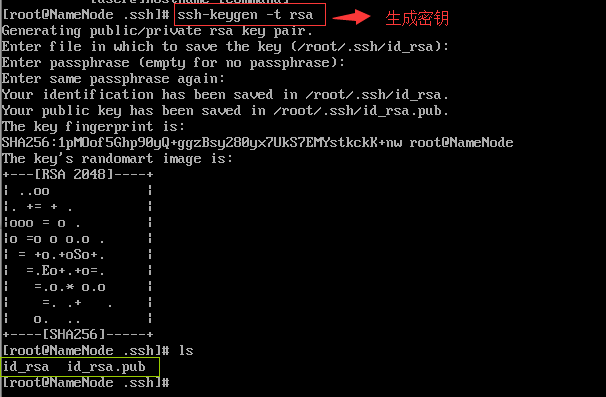
把五台电脑的id_rsa.pub里的数据复制到同一个文本里改名为authorized_keys然后给每台电脑拷贝一个到~/.ssh目录下就可以了
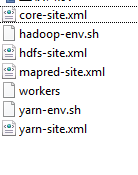
11.Hadoop配置文件的修改(重要)
需要修改的文件在/hadoop/etc/hadoop目录下
第一个core-site.xml 里添加如下 红色的部分为主机的ip或者主机名之前设置过hosts解析
<property>
<name>fs.defaultFS</name>
<value>hdfs://
NameNode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
第二个hadoop-env.sh在里面加入如下代码
export JAVA_HOME=/jdkexport HADOOP_HOME=/hadoop
第三个hdfs-site.xml 第一个红色和第二个红色部分为主机名和备份主机名或者ip都行第三个红色部分为默认备份几份
<property>
<name>dfs.namenode.http-address</name>
<value>
NameNode:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>
StandbyNameNode:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>dfs.replication</name>
<value>
2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data</value>
</property>
第四个mapred-site.xml通知hadoop使用yarn框架
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/hadoop/etc/hadoop,
/hadoop/share/hadoop/common/*,
/hadoop/share/hadoop/common/lib/*,
/hadoop/share/hadoop/hdfs/*,
/hadoop/share/hadoop/hdfs/lib/*,
/hadoop/share/hadoop/mapreduce/*,
/hadoop/share/hadoop/mapreduce/lib/*,
/hadoop/share/hadoop/yarn/*,
/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
第五个workers 里面加入DataNode1,DataNode2,DataNode3的ip地址或者主机名
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>
NameNode</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
start-all.sh 和 stop-all.sh 头部加入下面七句代码
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root start-dfs.sh和stop-dfs.sh 头部加入下面四句代码
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root stop-yarn.sh和start-yarn.sh头部加入下面三句代码
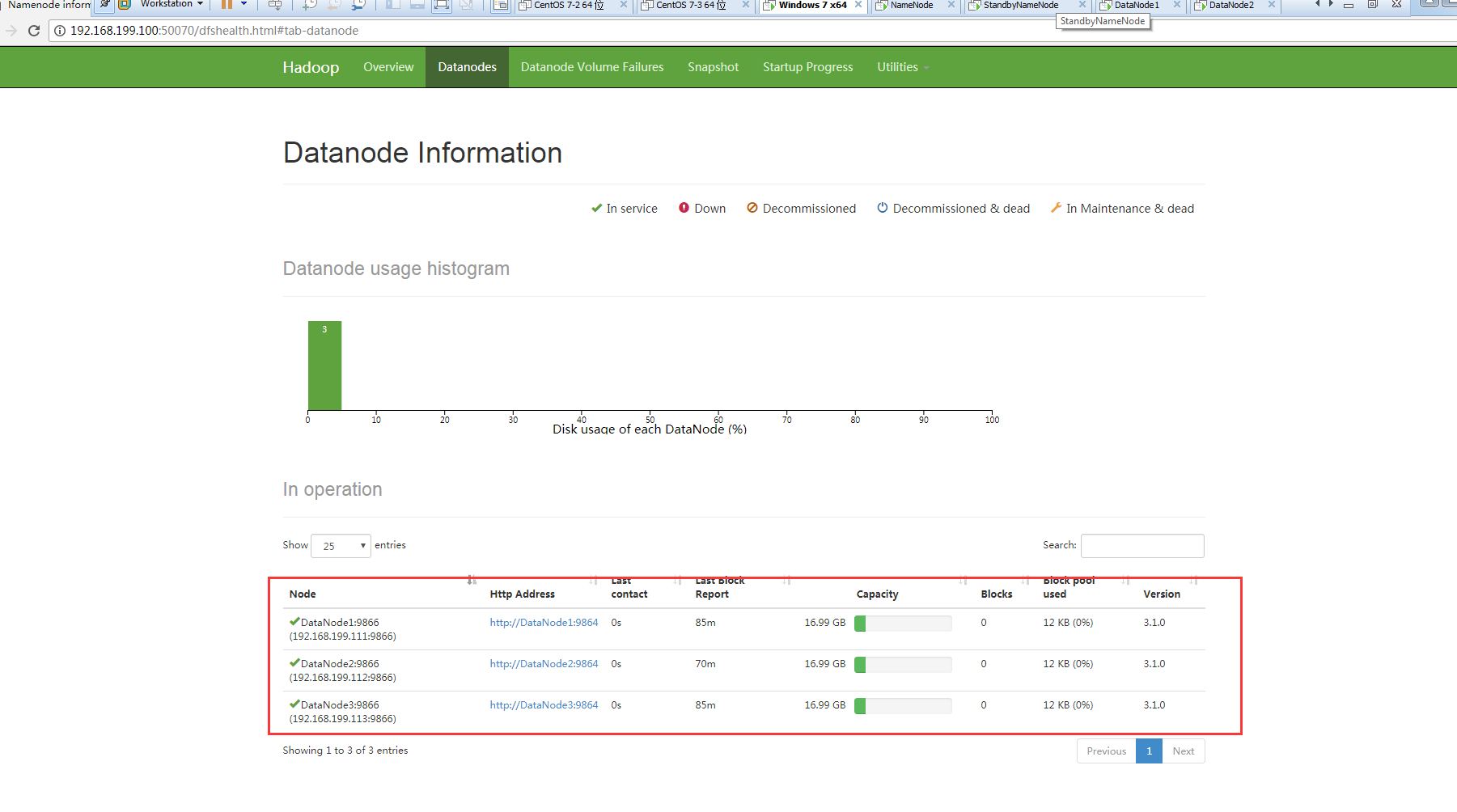
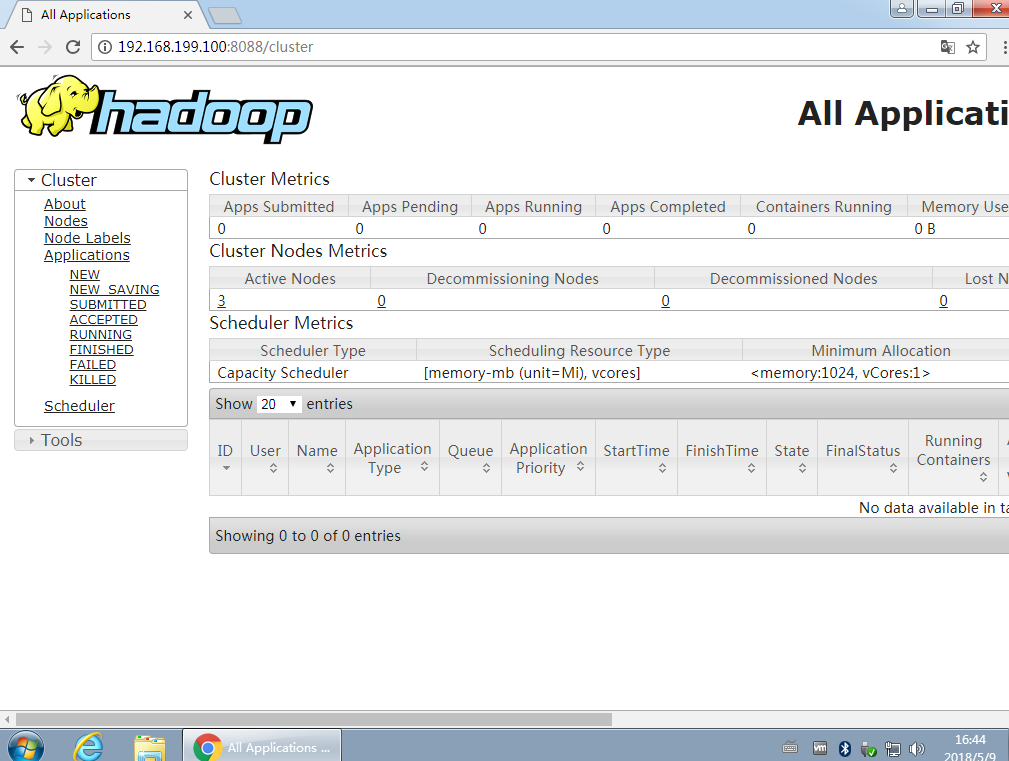
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root 主机的hadoop目录复制到其他所有电脑环境变量也复制到其他所有电脑然后输入hdfs namenode -format进行格式hadoop后重启所有电脑后再运行start-all.sh scp -r /hadoop/ 192.168.199.101:/ scp -r /hadoop/ 192.168.199.111:/ scp -r /hadoop/ 192.168.199.112:/ scp -r /hadoop/ 192.168.199.113:/ scp -r /etc/profile 192.168.199.101:/etc/ scp -r /etc/profile 192.168.199.111:/etc/ scp -r /etc/profile 192.168.199.112:/etc/ scp -r /etc/profile 192.168.199.113:/etc/ /hadoop/sbin/start-all.sh 最后进入http://192.168.199.100:50070和http://192.168.199.100:8088进入测试是否安装成功 在 mapred-site.xml
中添加如下代码 <property> <name>mapreduce.map.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>8192</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx3072m</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx6144m </value> </property> 注意检查 mapred-site.xml下的classpath <property> <name>mapreduce.application.classpath</name> <value> /hadoop/etc/hadoop, /hadoop/share/hadoop/common/*, /hadoop/share/hadoop/common/lib/*, /hadoop/share/hadoop/hdfs/*, /hadoop/share/hadoop/hdfs/lib/*, /hadoop/share/hadoop/mapreduce/*, /hadoop/share/hadoop/mapreduce/lib/*, /hadoop/share/hadoop/yarn/*, /hadoop/share/hadoop/yarn/lib/* </value> </property>